
大型网站核心优化之MySQL优化
Nginx
问题:输入IP地址无法访问
检查步骤:
- 检查服务是否启动(ps -A | grep nginx) 脚下留心:nginx支持php (/php/server/php/sbin/php-fpm)
- 检查防火墙例外是否添加(vi /etc/sysconfig/iptables service iptables stop)
- 检查本机输入的网址是否指向linux服务器(在本机DOS窗口输入 ping 网址)
复习
集群技术/冗余技术:多台服务器实现相同的业务
负载均衡:将用户的请求分配给不同的服务处理
动静分离:将静态资源脱离项目/Public目录而是单独服务器存储
现在很多大公司都是通过对象存储存放静态资源
主从复制:一台服务器有增/改/删时候,其它服务器会自动同步数据
读写分离:通过php判断insert/update/delete开头则去主服务器,select则去从服务器
CDN加速:CDN服务器供应商在全国各个城市都有一个机房,用于后期缓存静态资源,网站老板购买了CDN后,其网站用户访问时第一次去源服务器访问并缓存到用户最近的机房,下次直接去最近的机房(节点)访问。
面试:问现在网站打开比较慢你如何优化?
- 获取网站慢SQL语句
- 读写分离、主从复制
- 开启opcode缓存
- 开启CDN加速、开启懒加载、搭建负载均衡
- 等
一、MySQL优化概述
1、基本概念
上一讲说了主从复制、读写分离都是从查询角度优化、但最终必不可免的还是得操作数据库、思考如何从设计数据库角度优化?
2、优化策略
架构:读写分离、主从复制
设计:三范式、存储引擎、字段类型
功能:索引、分区、缓存
二、MySQL表的设计(三范式)
1、概念
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则(注:这个规则在关系型数据库中称之为三范式)
脚下留心:有些时候一味追求范式减少冗余,反而降低读写效率,这时候可以反三范式,利用空间来换时间。
概况
什么是三范式:就是设计数据库的规则
三范式的好处:减少冗余,加速读写数据
反三范式:不按规则出牌,通过冗余策略以空间换时间
2、确保每列/字段保持原子性(1NF)
1)概念
- 每列字段不可以再分
举例
- 案例:地区表
id(编号) address(地址) ? 不符合因为地区可以拆分成:省市区,一个字段后期可扩展性差
1 北京北京朝阳区
2 上海上海浦东新区
3 江苏泰州海陵区
2、有主键,非主键字段依赖主键(2NF)
1)概念
- 每个表必须有一个主键自增字段
- 一个表只描述一件事
2)举例
- 案例1:用户表
#用户表
id(用户编号) username(用户名) password(密码) 刚不符合因为一个表只描述一件事
#收货地址表
address(收货详细地址) tel(联系人电话) 用户编号
- 案例2:订单表
订单编号 订单总价 订单总数量 所属用户 产品ID 产品名称 产品单价 …
1 20 2 1 1 xxx 10
2 20 2 1 1 xxx 10
订单(主)
订单编号 订单总价 订单总数量 所属用户
订单(从) 产品
ID 订单主表编号 产品ID 产品单价 ………
3、消除传递依赖,非主键字段不能相互依赖(3NF)
1)概念
- 一个表不能包含其他表的非主键字段(一个表只能包含其他表的主键)
2)举例
#文章表
文章编号 文章标题 文章内容 用户ID 用户姓名 (文章表不能包含其他表的非主键字段,所以用户名移除,后期需要获取文章的作者,直接通过多表查询即可)
#用户表
用户ID 用户姓名 用户年龄 …
4、逆范式
1)概念
符合范式设计是为了减少冗余提高读写效率,但有时候我们需要反其道而为之,利用空间来换时间(数据冗余策略),该设计被称之为“逆范式”
2)举例
- 案例1:
【场景】查看文章详情,评论总数
【表】
#文章表
编号 标题 内容 评论总数…
#评论表
编号 所属用户 所属文章 评论内容 ….
正常流:select count(*) from 评论表 where article_id = 文章ID
逆范式:再文章表增加一个字段(评论总数),每次用户评论成功后,给文章表的评论总数字段+1
- 案例2:
收货地址表
编号 姓名 省 市/区 乡镇 详细地址 ….
1 你爸爸 阿富汗 xxx xxx
2 杨文杰
3 娇娇
订单(主表)
订单ID 总价 数量 订单状态 支付状态 收货地址表编号… (不合理,因为后期用户在发货的时候删除或者修改,再找商家麻烦,问题就大了,解决采用冗余策略)
1 1000000000 1 已发货,待收货 已支付 1
订单(从表)
商品ID 商品名称 商品价格 …
订单(收货地址表)
姓名 省 市/区 乡镇 详细地址
︴总结
- 什么是三范式:就是设计表的规则
- 三范式好处:减少冗余,提高读写效率
- 三范式有哪些:
- 每个字段不可以拆分
- 每个表必须有主键自增、每个表只描述一件事
- 一个表不能包含其他表的非主键字段
- 逆范式:反三范式规则、以空间换时间(冗余策略)
︴说明
前期别想太多根据页面显示数据设计表(一般一个显示对应一个字段)
其次常用字段推荐:
1)编号,主键自增
2)创建于,便于后期数据赛选统计
3)更新于,便于后期数据赛选统计
4)是否显示,便于逻辑删除数据
三、存储引擎
1、什么是存储引擎
- 说明:
MySQL中按照一定的数据格式来保存最终的数据,通过存储引擎来指定哪种方式存储方案。
- 常用的存储引擎:innodb 和 myisam
- 查看当前MySQL支持的存储引擎列表:show engines;
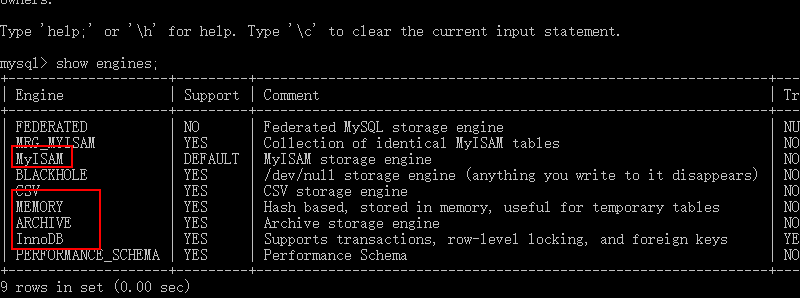
2、myisam存储引擎
1)概念
<= 5.5 MySQL默认的存储引擎。
如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且
对事务的完整性要求不是很高;其优势是访问的速度快,擅长与处理高速读与写。
应用场景
对事务完整性要求不高,不涉及钱的表
3)存储方式
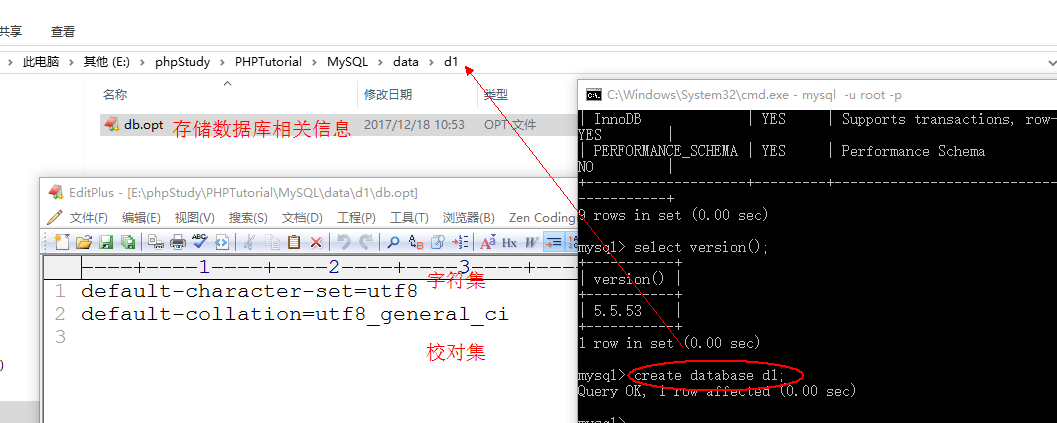
- 创建数据库:create database d1;
- 说明:创建数据库会在MySQL的data目录下创建同名文件夹
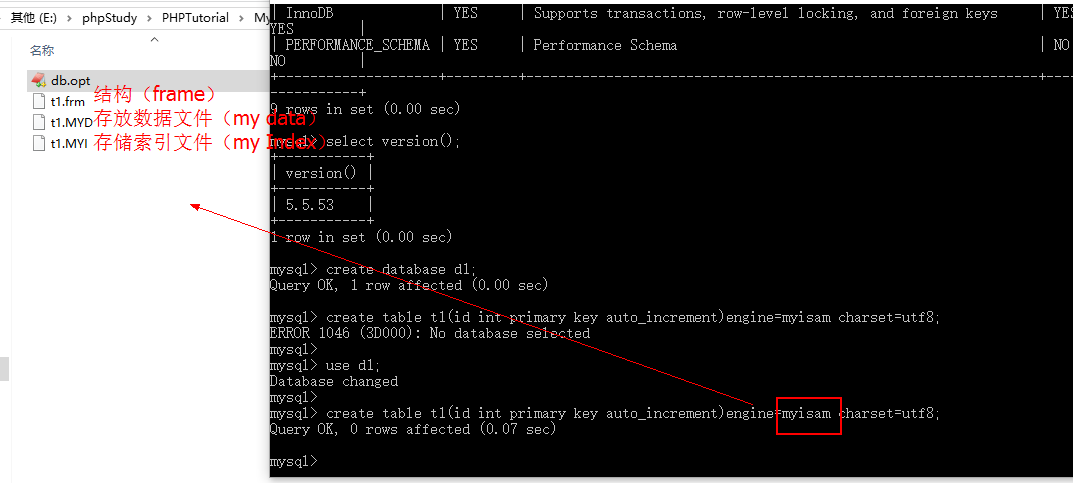
- 创建myisam表:
- create table t1(id int primary key auto_increment)engine=myisam charset=utf8;
3、innodb存储引擎
1)概念
>=5.5 默认的存储引擎,MySQL推荐使用的存储引擎。
提供事务,行级锁定,外键约束的存储引擎。
事务安全型存储引擎。更加注重数据的完整性和安全性。
2)应用场景
订单、账户、积分等
3)存储方式
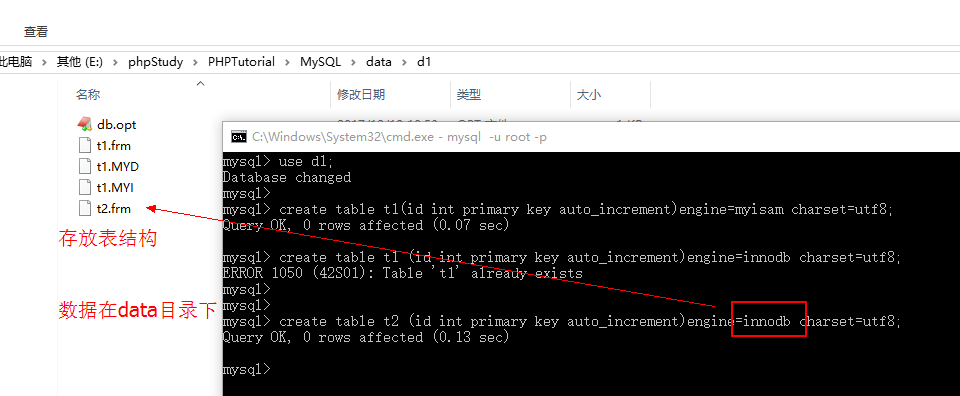
- 创建innodb存储引擎数据库:
- create table t2 (id int primary key auto_increment)engine=innodb charset=utf8;
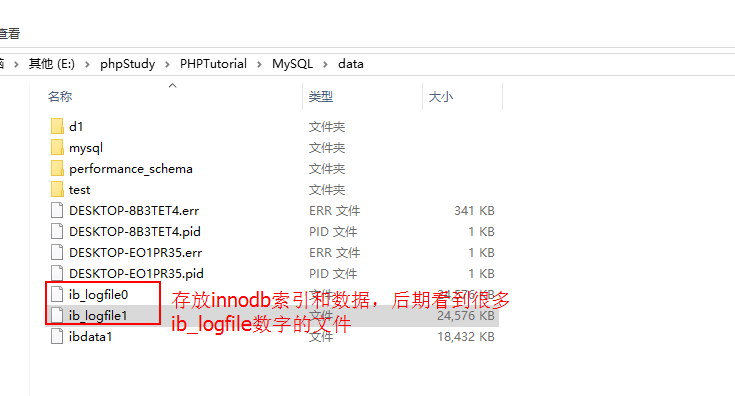
多学一招:
myisam因为结构、索引、数据都存放在数据库文件夹下,所以可以直接复制迁移,而innodb都存在ib_logfile数字文件中,在存储的时候记录了使那个数据的表,所以后期无法迁移。
Archive存储引擎(存档型)
1)说明
该类型只能插入和读取不能修改和删除。
举例
应用场景
网站管理员操作日志
5、Memory存储引擎(内存型)
简单了解,该类型将数据保存在内存(后期通过通过memcache、redis软件代替)
内存存储 > 文件缓存 > 数据库存储
6、MyIsam和InnoDB存储引擎区别(面试笔试)
- 存储结构:myisam三个文件,innodb一个文件
- 锁:myisam表级锁,innodb可表可行级锁
- 事物和外键支持:innodb都支持,myisam都不支持
- CURD操作:
MyISAM:如果执行大量的SELECT,MyISAM是更好的选择。
InnoDB:如果你的数据执行大量的INSERT或UPDATE,出于性能方面的考虑,应该使用InnoDB表。DELETE 从性能上InnoDB更优,但DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的删除,在innodb上如果要清空保存有大量数据的表,最好使用truncate table这个命令。
- 全文检索:MySQL5.6以下innodb不支持(都不支持中文)
列类型的选择
概念
1)“字节”的定义
- 字节(Byte)是一种计量单位,表示数据量多少,它是计算机信息技术用于计量存
储容量的一种计量单位。
1字节(Byte)= 8位(bit)
1KB = 1024Byte(字节)
1MB = 1024KB
1GB = 1024MB
1TB = 1024GB
2)字节和字符的区别
https://zhidao.baidu.com/question/454436588167256525.html
英文:1个字符 = 1个字节
中文:1个字符 = 等于3个字节
MySQL类型字符和字节相关细节
整型 字节
char 范围:字符 括号中的数字:字符
varchar 范围:字节 括号中的数字:字符
1、为什么要学习列类型优化
以前的时候都是直接凭感觉选择字段,这样就造成了两个问题
1)浪费磁盘空间
2)降低读写效率
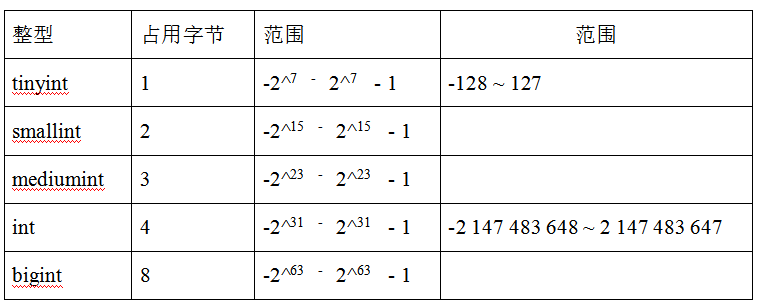
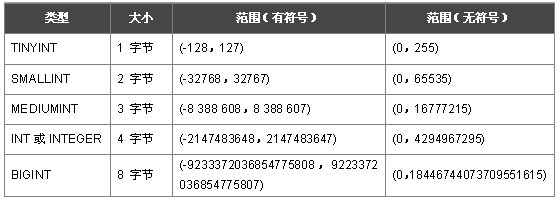
2、整型
1)说明
︴案例
- 存储人的年龄应该使用哪种数据类型?
答:tinyint(3)
整型括号中的数字仅仅只有增加zerofill属性时才生效,表示插入数据如果不够宽度则补零
误区1:tinyint(1) 不能插入1位以上数字 错
误区2:tinyint(3) 占1个字节
年龄:tinyint(3)
性别:tinyint(1)
声明如果没有明确zerofill属性则两者没有区别,但是为什么年龄写3,性别写1呢?目的:增强代码可读性
- 存储乌龟的年龄应该使用哪种数据类型?(千年王八万年龟)
答:smallint
- 存储一个1500万数据的数据表其主键id应该选择哪种数据类型?
答:int
3、字符串型
1)说明
char 固定字符串类型(0-255个字符)
varchar 可变字符串类型(0-65535个字节) utf8字符:65535/3=21845
char(字符)
varchar(字符) utf8=21845个字符 gbk=32767个字符
字符表示:任意中文、数字、英文组合插入不能超过指定字符即可,如:char(3)表示可以插入任意3个英文、数字、中文组合。
︴案例
- 存储11位手机号码,选择?
答:char(11) 说明:从效率占用空间选择bigint,但是从可扩展性选择char
bigint 8个字节 (int不能4个字节,最大长度10位)
char(11) 代表11个字符,utf8=因为数字11个字节
- 存储md5加密的密码,选择?
答:char(32) 因为php的md5加密32位
http://www.cmd5.com/ 在线破解
- 存储标题或姓名,选择?
答:varchar(45)
标题推荐80有利于seo优化(seo优化指:在百度输入你的名字可以找到你)
http://seo.chinaz.com/?q=www.itcast.cn

- 存储描述信息(不超过250个汉字),选择?
答:varchar(200)
- 存储文章内容,选择?
答:text
时间类型
|
数据类型 |
描述 |
格式 |
占用字节 |
|
datetime |
日期时间 |
年-月-日 小时:分钟:秒 |
8 |
|
date |
日期 |
年-月-日 |
4 |
|
time |
时间 |
小时:分钟:秒 |
3 |
|
year |
年份 |
年 |
1 |
|
timestamp |
时间戳 |
年-月-日 小时:分钟:秒 |
4 |
- 在实际工作中推荐使用int类型
原因1:空间(int占4 datetime占8个字节)
原因2:格式(2013年11月、2013/11/11、2013-11-4、【刚刚 1分钟前 一年前】)
多说两句
- 任然有部分小公司使用datetime类型
- int类型最大存储时间2038年
5、枚举类型与集合类型
在实际应用中,如果程序中有单选或多选情况,不建议使用varchar类型,而建议使用枚举类型或集合类型 或 用整型代替。
enum: 枚举单选 enum(‘男’, ‘女’, ‘保密’)
set: 集合多选 set(‘语文’, ‘英语’, ‘物理’)
说明:实际工作中推荐使用int
原因:因为enum是mysql独有的,可扩展想不强(不能迁移)
性别:tinyint(1) 性别:1-男,2-女
场景:查询user表所有男生
以前:select * from user where sex = 1;
框架:D(‘user’)->where(‘sex = 1’)->select();
优化:
步骤1:在模型中定义常量
const SEX_MAN = 1;
const SEX_WOMEN = 2;
步骤2:查询
D(‘user’)->where(‘sex = ‘.USER::SEX_MAN)->select();
<?php
//订单类
class Order
{
const STATE_WAIT_TO_PAY = 1; // 待支付
const STATE_PAID_SUCCESS = 2; // 已支付(成功)
const STATE_PAID_TIMEOUT = 5; // 已支付(超时)
const STATE_PAID_CANCEL = 8; // 已付款(但在通知到来前取消)
const STATE_TIMEOUT = 7; // 超时未支付
const STATE_CANCELED = 6; // 已取消
const STATE_REFUNDED = 9; // 已退款
}
state:1-xxx,2-xxxx,3-xxx
select * from Order where state = 2 需要打开数据库看
select * from Order where state = Order::STATE_WAIT_TO_PAY 增强代码可读性
6、数值型(小数)
- decimal、float、double都是小数,decimal相对后两个更精确但是占用空间
- 未涉及到资金小数可以用浮点型(float或double) 优先用float
- 涉及资金用decimal(注:decimal小数位一般2位如果没有小数会用0自动补充)
- decimal(10, 2)
7、IP类型数据的存储
- ip选择整型
XXX.XXX.XXX.XXX char(15字符串 15字节)
ip2long
long2ip int 4字节
五、慢查询日志(查询需要优化的SQL语句)
1、作用
思考:新人加入,项目中编写SQL语句可能存在问题,问如何检查
解决:通过慢查询日志(在MySQL中修改配置文件,从而可以记录查询找过指定是按的SQL语句)
2、测试SQL语句
#创建表
create table php_slow_log2 (
name varchar(300),
name2 varchar(300)
)engine=innodb charset=utf8;
#插入数据
insert into php_slow_log2 values
(‘zzzzzz’,’zzzzzz’),
(‘zzzzzz’,’zzzzzz’),
(‘zzzzzz’,’zzzzzz’),
(‘zzzzzz’,’zzzzzz’);
#Mysql蠕虫复制
insert into php_slow_log2(name,name2) select name,name2 from php_slow_log2;
insert into php_slow_log2(name,name2) select name,name2 from php_slow_log2;
insert into php_slow_log2(name,name2) select name,name2 from php_slow_log2;
insert into php_slow_log2(name,name2) select name,name2 from php_slow_log2;
insert into php_slow_log2(name,name2) select name,name2 from php_slow_log2;
insert into php_slow_log2(name,name2) select name,name2 from php_slow_log2;
insert into php_slow_log2(name,name2) select name,name2 from php_slow_log2;
insert into php_slow_log2(name,name2) select name,name2 from php_slow_log2;
insert into php_slow_log2(name,name2) select name,name2 from php_slow_log2;
3、实际操作
1) 使用如下指令查看慢查询日志是否开启
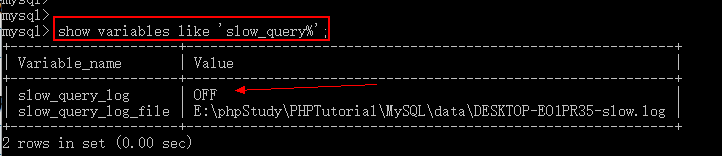
2) 手工开启慢查询日志
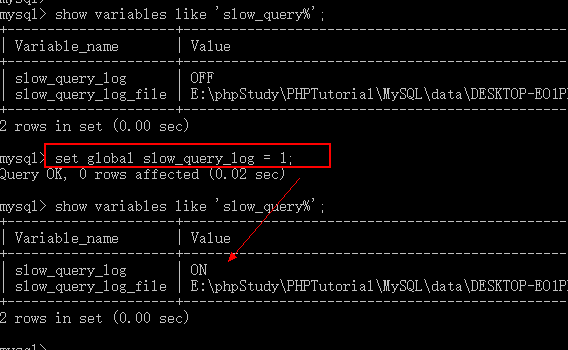
3) 设置查询的临界时间(查询超过指定时间后纪录)
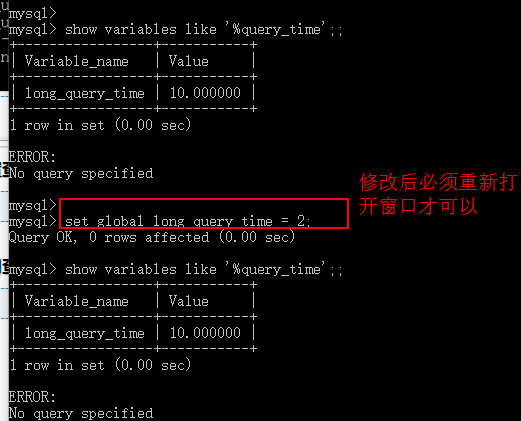
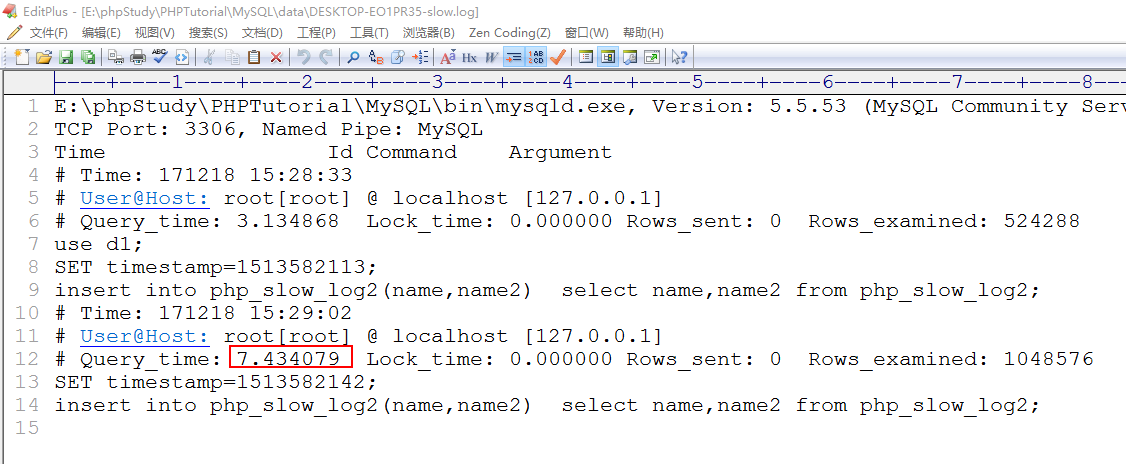
4) 使用查询语句(超时)
︴总结
步骤1:开启慢查询日志
set global slow_query_log = 1;
查看是否开启:show variables like ‘slow_query%’;
步骤2:设置时间
set global long_query_time = 2; #注:2秒
查看时间:show variables like ‘%query_time’;
步骤3:关闭当前DOS窗口重新登录执行慢SQL语句,查看文件是否记录即可
六、数据库设计中的索引
1、什么是索引
索引相当于书目录,加快访问速度
2、现实生活中的索引

3、索引的好处
- 好处:加快访问速度
- 坏处:
- 索引占用磁盘空间
- 索引会影响SQL语句执行速度,因为增加/修改都需要更新索引
索引可以加快查询效率,但是也不能滥用索引,否则适得其反
4、四种索引形式
普通索引(index) – 仅仅为了加快查询速度
唯一索引(unique) – 保证数据唯一性
主键索引(primary key) – 既保证数据唯一不能为null
全文检索(fulltext) – 提取指定字段的关键字,添加索引
组合索引 – 同时给两个字段设置相同的索引
5、建表时创建索引
#【需求】
编号 – 主键索引
姓名 – 唯一索引
密码 – 普通索引
a和b – 复合/组合索引
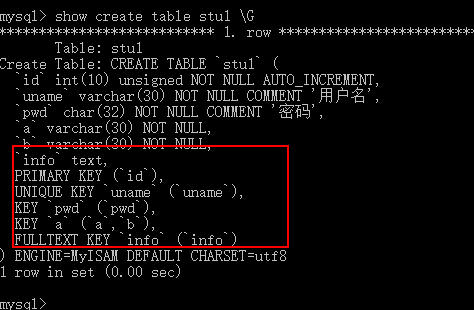
info – 全文索引
#【创建索引表】
create table stu1(
id int unsigned auto_increment,
uname varchar(30) not null comment ‘用户名’,
pwd char(32) not null comment ‘密码’,
a varchar(30) not null,
b varchar(30) not null,
info text,
?????
)engine=myisam charset=utf8;
#【查看索引表】
create table stu1(
id int unsigned auto_increment,
uname varchar(30) not null comment ‘用户名’,
pwd char(32) not null comment ‘密码’,
a varchar(30) not null,
b varchar(30) not null,
info text,
primary key(id),
unique (uname),
index (pwd),
index (a,b),
fulltext (info)
)engine=myisam charset=utf8;
修改表的结构增加索引 和 删除索引
1)需求
create table user2 (
id int unsigned ,
uname varchar(30) not null comment ‘姓名’,
pwd char(32) not null comment ‘密码’,
a varchar(10) not null comment ‘a’,
b varchar(10) not null comment ‘b’,
info text
)engine=MyISAM charset=utf8;
2)语法
- 修改表添加索引:alter table 表名 add 索引类型 索引名(待添加索引字段)
- 删除表指定索引:drop index 索引名 on 表名
索引名字推荐使用字段名+索引名
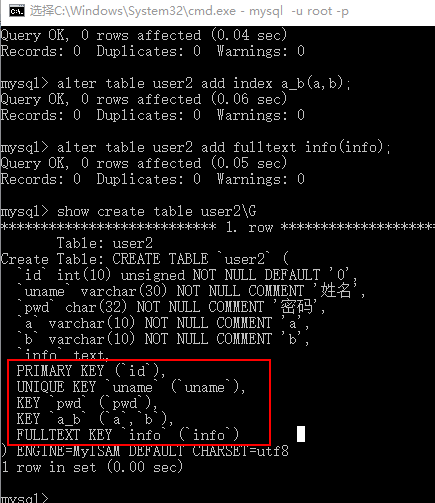
3)SQL语句
#【需求】
编号 – 主键索引
姓名 – 唯一索引
密码 – 普通索引
a和b – 复合/组合索引
info – 全文索引
#【创建索引】
alter table user2 add primary key id(id);
alter table user2 add unique uname(uname);
alter table user2 add index pwd(pwd);
alter table user2 add index a_b(a,b);
alter table user2 add fulltext info(info);
#【删除索引】
7、创建索引原则
用于频繁搜索的列
用于排序的字段
做条件查询的列
给字段数据尽量不重复的字段添加索引,如:编号
七、千万级数据量根据索引优化查询速度
八、MySQL中的执行计划
SQL
#创建数据库
create database php666;
#选择数据库
use php666;
#创建表
create table stu (
id int unsigned primary key auto_increment comment ‘编号’,
name varchar(10) not null comment ‘姓名’,
sex char(2) not null default ‘男’ comment ‘性别’,
age tinyint(3) not null default 0 comment ‘年龄’,
money decimal(10,2) not null default 0 comment ‘资金’,
address varchar(200) default ” comment ‘地址’
)engine=myisam charset=utf8;
#学生数据插入
insert into stu
values
(null,’小泽’,’男’,18,30.56,’北京’),
(null,’苍苍’,’男’,40,80,’日本’),
(null,’小白’,’男’,30,10,’哈尔滨’),
(null,’小黑’,’男’,18,76,’黑龙江’),
(null,’小弟弟’,’女’,18,76,’北京’),
(null,’老陆’,’女’,88,44,’上海’),
(null,’校长’,’男’,100,20,’上海’);
#分数表
create table score (
stu_id int unsigned comment ‘关联学生表ID’,
id int unsigned primary key auto_increment comment ‘分数表ID’,
math int unsigned not null comment ‘数学’,
chinese int unsigned not null comment ‘语文’,
english int unsigned not null comment ‘英语’
)engine=myisam charset=utf8;
#分数数据插入
insert into score
values
(1,null,80,58,99),
(2,null,11,99,29),
(3,null,32,53,89),
(4,null,99,28,99),
(5,null,77,68,19),
(6,null,33,18,29);
1、什么是MySQL中执行计划
就是通过explain关键词分析SQL语句
2、explain语法
使用:直接explain后面写SQL语句
语法:explain SQL语句 \G
说明:\G后面不需要加分号
3、使用explain执行计划分析
1)说明
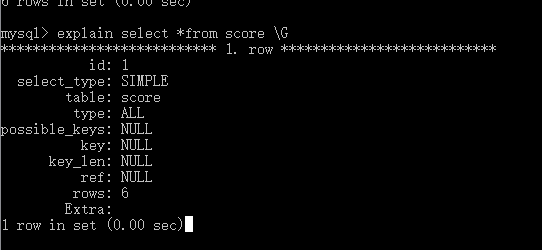
select_type – 查询类型
table – 表名
type – 连接所使用的类型
possible_keys – 可能使用的索引
key – 实际使用索引
key_len – 索引长度
rows – 可能需要检索的行数
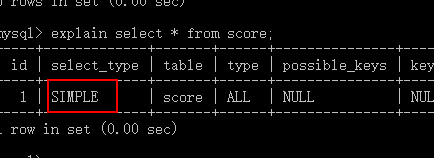
2)分析,查询类型(select_type)
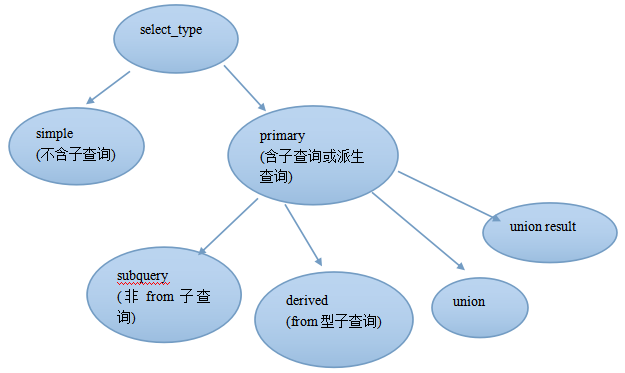
#情况1:simple
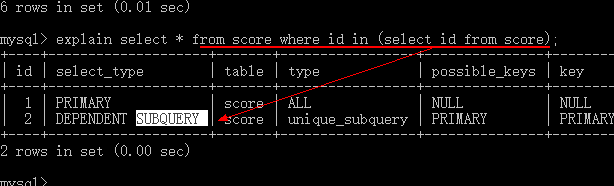
#情况2:subquery
#情况3:derived

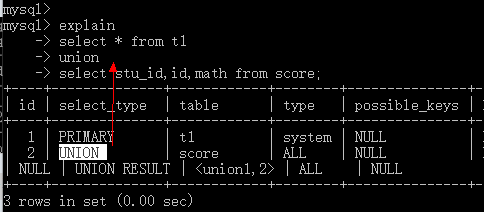
#情况4:union
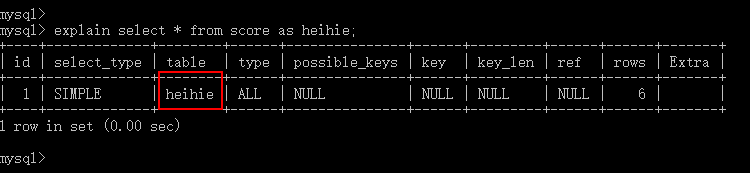
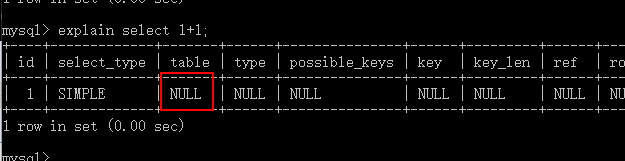
3)分析,表名(table)
#情况1:实际表名

#情况2:表别名
#情况3:derived (from型子查询)
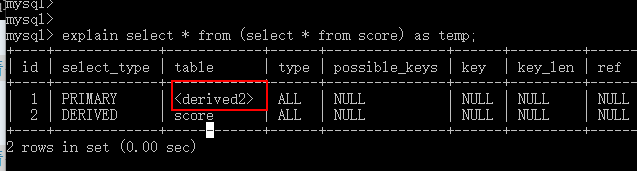
#情况4:null
4)分析,额外项(extra)
index: 是指用到了索引覆盖,效率非常高
using where 是指光靠索引定位不了,还得where判断一下
extra 中出现以下 2 项意味着 MYSQL 根本不能使用索引,效率会受到重大影响。应尽可能对此进行优化
using temporary
表示 MySQL 在对查询结果排序时使用临时表。常见于排序 order by 和分组查询 group by。
using filesort
表示 MySQL 会对结果使用一个外部索引排序,而不是从表里按索引次序读到相关内容。可能在内存或者磁盘上进行排序。MySQL 中无法利用索引完成的排序操作称为“文件排序”
5)分析,连接所使用的类型(type)【重要的项分析】
- 这一列的常见值有:const、all、range、system、index
最好的是 system , 一般在表中只有一行记录的或者查询系统表的时候出现。
其次就是 const, 一般在使用主键索引的时候会出现。
其其次range, 一般在做范围查询的时候会使用 id < 100。
index, 代表可以使用索引做一些优化,一般在查询表的总行数的时候出现。
all, 一般使用不上索引的时候出现。
ref, 意思是指 通过索引列,可以直接引用到某些数据行
eq_ref, 意思是指 通过索引列,可以直接引用某1行数据
- 场景
#情况1:system
#情况2:const

#情况3:range
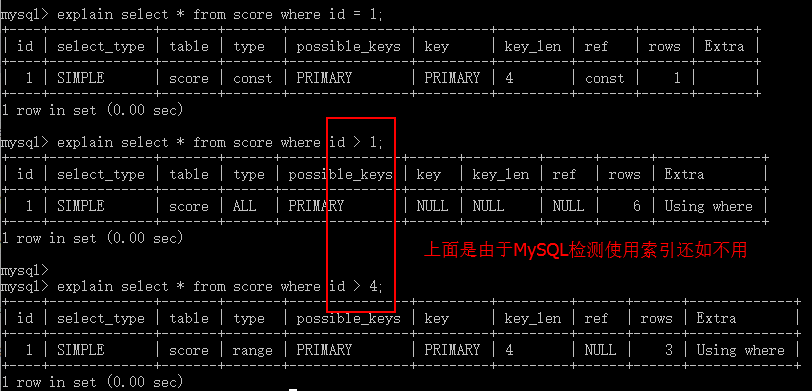
#情况4:all
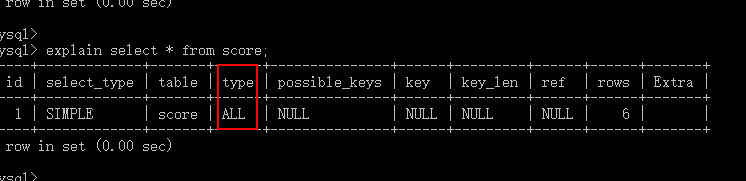
4、索引的使用原则(哪些常见情况不能用索引?)
说明
- like查询(“%”和“_”开头)索引失效 (sphinx网站中全站检索)
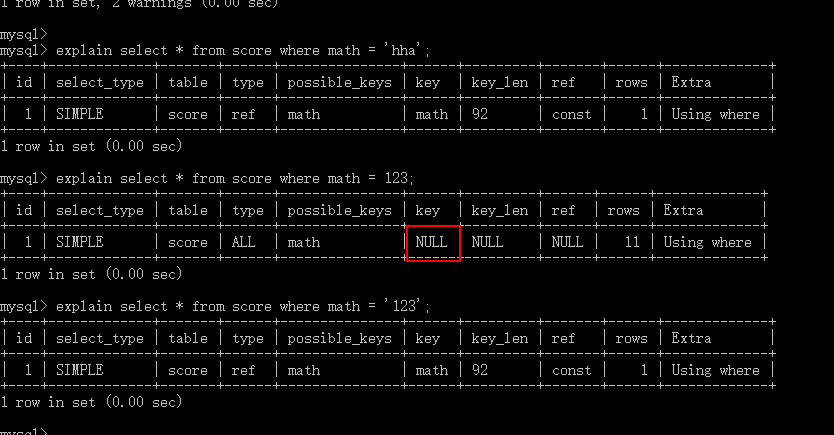
- or运算都要具有索引否则索引失效
- where条件字符串必须加引号
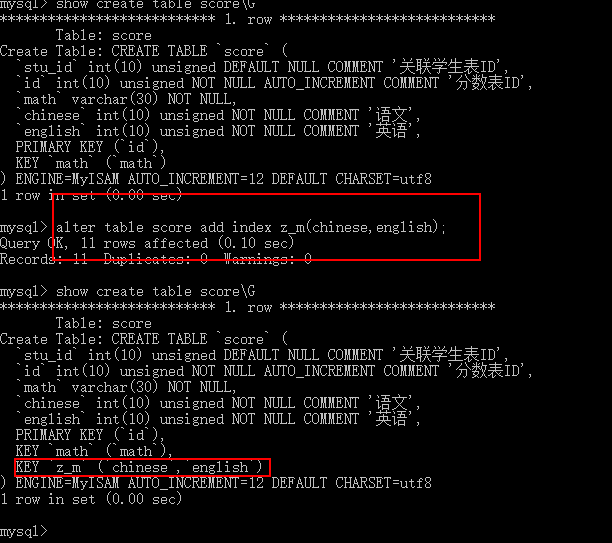
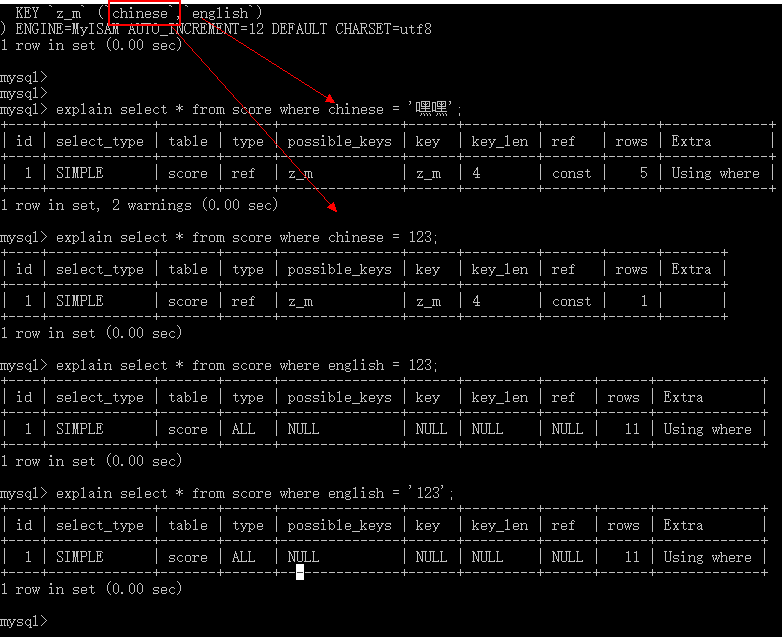
- 组合索引字段单独使用,左边生效,右边失效(左原则)
验证
- like查询(“%”和“_”开头)索引失效 (sphinx网站中全站检索)
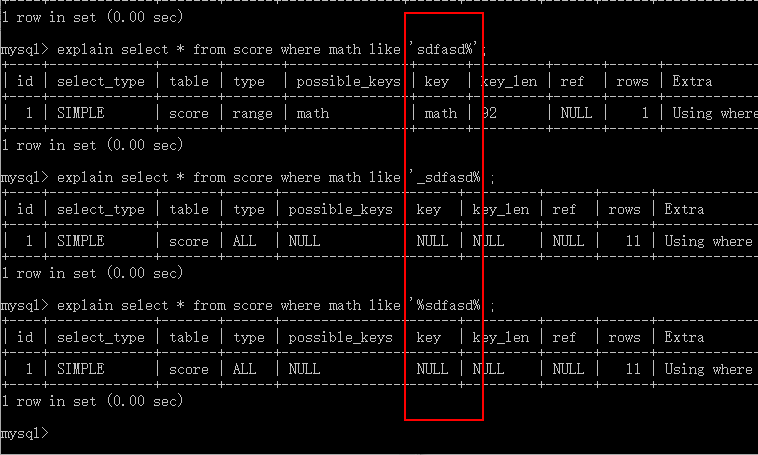
- or运算都要具有索引否则索引失效

- where条件字符串必须加引号
- 组合索引字段单独使用,左边生效,右边失效(左原则)
总结
MySQL如何优化?
架构:读写分离、主从复制
设计:三范式、逆范式、存储引擎的选择、字段类型
功能:索引、缓存、分区
——————————
什么是三范式:就是设计表的规则
三范式好处:减少冗余,提高读写效率
三范式有哪些:
1)每个字段不可以拆分
2)每个表必须有主键自增、每个表只描述一件事
3)一个表不能包含其他表的非主键字段
逆范式:反三范式规则、以空间换时间(冗余策略)
多学一招:强烈推荐一个表有哪些基本字段(id、created_at、updated_at、display:1-显示,2-隐藏)
————————————–
存储引擎:myisam 、 innodb 、 archive 、 memory
myisam和innodb区别
存储结构:myisam三个文件,innodb一个文件
锁:myisam表级锁,innodb可表可行级锁
事物和外键支持:innodb都支持,myisam都不支持
CURD操作:
MyISAM:如果执行大量的SELECT,MyISAM是更好的选择。
InnoDB:如果你的数据执行大量的INSERT或UPDATE,出于性能方面的考虑,应该使用InnoDB表。DELETE 从性能上InnoDB更优,但DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的删除,在innodb上如果要清空保存有大量数据的表,最好使用truncate table这个命令。
全文检索:MySQL5.6以下innodb不支持(都不支持中文)
——————————————–
什么是索引:相当于书的目录,加快访问速度
索引的好处:加快访问速度
瑕疵:占用磁盘空间,影响读写速度,因为需要更新索引
创建索引:alter table 表名 add 索引类型 索引名(字段名);
删除索引:drop index 索引名 on 表名
——————————————-
普通索引(index) – 仅仅为了加快查询速度
唯一索引(unique) – 保证数据唯一性
主键索引(primary key) – 既保证数据唯一不能为null
全文检索(fulltext) – 提取指定字段的关键字,添加索引
组合索引 – 同时给两个字段设置相同的索引
——————————————-
什么是MySQL中的执行计划:通过explain关键字分析SQL语句
索引使用规则
like查询(“%”和“_”开头)索引失效 (sphinx网站中全站检索)
or运算都要具有索引否则索引失效
where条件字符串必须加引号
组合索引字段单独使用,左边生效,右边失效(左原则)

